文/謝邦昌、謝邦彥
抽樣數據與大數據
以往進行民意調查,大多是透過電話抽樣,樣本數會做到抽樣誤差在正負3% 以內,在網路媒體與指尖行為還沒出現時,這種以統計抽樣為核心的民意調查方式對於選情的預測,有著相當不錯的準確度,如1996年總統大選、1998年台北市長選舉等。隨著網路資訊發達及行動通訊的重度使用發展趨勢,民眾在網路上留下了大量的數據,讓以往的抽樣調查,已經無法涵蓋現代人的生活形態。
在過去的十年間,數據爆炸已經成為人所共知的一個話題,根據市場研究公司IDC去年發佈的數據,預估2009年到2020年期間,數字資訊總量將增長44倍。加上視頻、圖片、音頻等等非結構化豐富的媒體數據的應用越來越頻繁,社交網路的不斷增長和壯大;目前,每天光是流向社群網站Facebook與Twitter的資料量,就多達3億張照片、25億則發文、27億按讚數。大數據海嘯撲嘯而來,這些數據散布在各個地方,每天光速成長,數據既多,也雜亂,但好處是完整詳細。因此,這些都是「資訊完整的寶庫」
而大數據(Big Data)時代和一般資料庫分析有什麼不一樣的地方?就是除了有跟山一樣高的繁多資料外,還有許多對於非結構化資料的蒐集與分析。網路媒體有別於傳統媒體,每個使用者都可以製造、生產訊息,網路上的訊息量比美國國會圖書館還多了N^N倍,這些資料都不是整理好的資料,甚至大多不是數值資料,為了蒐集並且分析這些資料,文字探勘(Text Mining)成了近幾年的主流,分析出來的結果比抽樣更準確、更有價值。
因此,在現今汪洋數據的時代中,除了能利用量化的資料去分析外,質化的資料中更含有大量的資訊,如何利用「多維度的數據」幫客戶創造價值,正是文字探勘(Text Mining)的價值。將文字和數字一起分析幫客戶找出致勝密碼,並利用大數據和抽樣數據,讓產生的資料更有價值,精準的瞭解預測民意。
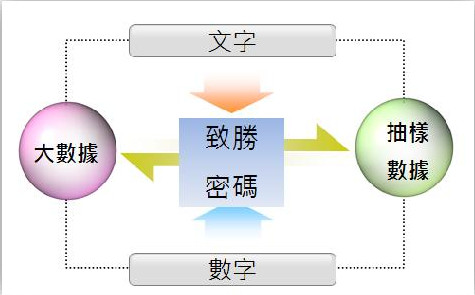
▲利用多維度的數據創造價值。
文字探勘的致勝密碼
文字探勘(Text Mining) 是一種跨領域的應用,結合資料探勘技術與自然語言處理、資訊檢索技術,使大量的文字資訊能經由電腦分析歸納,主要的應用有自動分類、自動摘要、文件檢索、知識管理等。用以因應今日因網際網路(Internet) 興起,而造成的龐大的數據洋流。
文字採礦之核心技術,大多來自於資料採礦技術,將藉助案例分析與文件資料之相互查詢與交叉比對,產生經驗與文件報告之交互參考對應。
近年來由於網路的發展,電子文件呈現等比級數的成長,每天均有龐大文件資料被製造生產出來,這些各式各樣的文件,包括消費、廣告等一般資訊或者是社會、經濟、政治等即時新聞,都蘊藏著大量資訊,一旦文件暴增到數以百計或數以千計時,文件與文件之間毫無關聯,龐大的文件成為一堆資料山,要在短時間內閱讀或是查詢某一主題資訊,將很困難,因而喪失及時資訊或機會(黃燕萍,1999)。
文字知識發掘(Knowledge Discovery from Text ,KDT)亦可稱為文字探勘(Text Mining )或是文件資訊探勘(Document Information Mining )其應用了資訊檢索、資訊萃取、計算語言學、自然語言處理、資料探勘技術…等,文字探勘特別著重於利用這些技術,自非結構或半結構的文字中發掘出先前未知,隱含而有用的資訊,Dan Sullivan (2001)定義文字探勘為「一種編輯、組織及分析大量文件的過程,為了提供特定使用者特定的資訊,以及發現某些特徵及其間的關聯」。相較於傳統的資料探勘,文字探勘需要加上額外的資料選擇處理程序,以及複雜的特徵萃取步驟。
文字探勘整合了許多傳統資訊檢索技術,包括了關鍵字萃取、全文檢索、文件自動分類、自動摘要等等,以提供文字處理更強大的功能。
隨著電腦設備及網路技術的蓬勃發展和快速普及,許多傳統的資訊作業方式因此而改變,大量原本是以書面方式存在的文件資訊,被轉換成電子檔的形式來儲存及傳遞,而這些文件中極可能隱藏著許多有用的寶貴知識。但是,當資訊的產生和傳遞效率加速提昇時,也隱含了資訊爆炸的現象,然而,傳統資訊檢索方式無法有效地幫助使用者分析和了解大量的文件資料,許多試圖從文件中獲取知識的研究便因此而產生。
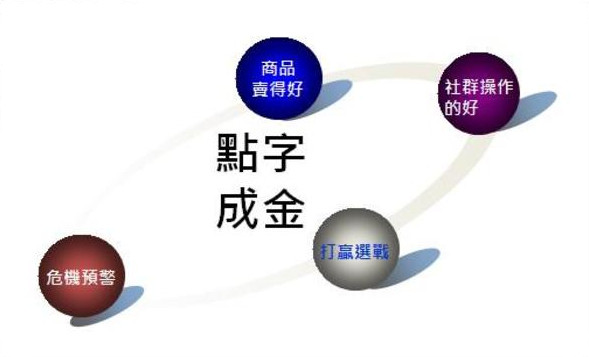
點字成金穩操勝券
以下為利用文字探勘(Text Mining)點字成金之案例,包含:商品要賣得好、社群操作的好、危機預警等。
1. 商品賣得好
想要商品賣得好,不外乎瞭解消費者想要的(want)。可以利用社群網站的資料詞雲分析,也可以利用調研,或是資料庫的分析等,如利用社群詞雲,分析PTT的討論區,可以看出網民透過”淘寶”網購,購買特殊品牌的包包及洋裝,這些資訊就可以做為通路產品採購策略的參考,推出大家都想要的商品,商品自然賣得好。

2. 社群操作得好
我們也可以從社群網站中挖掘出許多資料,如:利用粉絲的發文找出主題推論分析。如一個美妝FB粉絲團,我們可以看出它是以「吸引男友」、「創造自己在姊妹淘中的優越感」為訴求主軸,創造粉絲的需求,提升商品銷量。
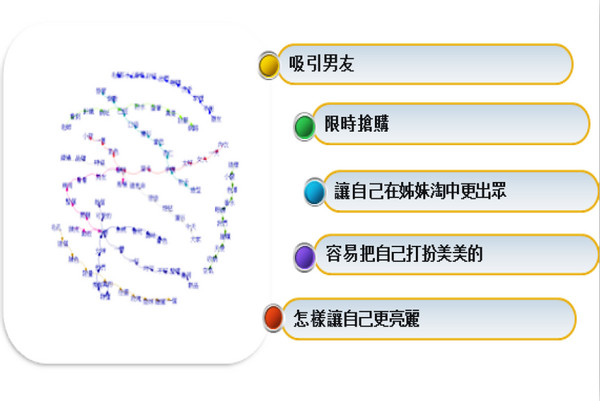
▲操作主題分析。
3. 危機預警
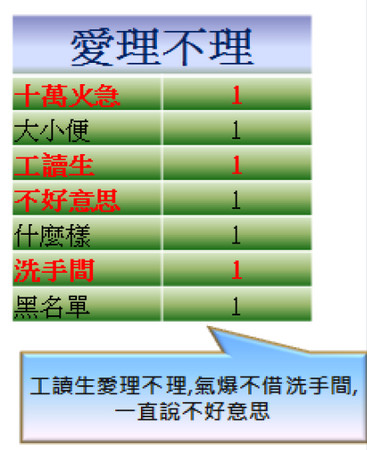
觀察粉絲團的po文動態,即時發現民眾對某便利超商工讀生在氣爆事件發生後的態度。。我們可以從特定的字詞中,找出與之相關聯的字詞,並從這些字詞裡找出價值性,如:與「愛理不理」相關聯的字詞,有「十萬火急」、「工讀生」、「不好意思」和「洗手間」,再從po文中還原出在高雄氣爆發生時,工讀生面對災民想要借用洗手間,礙於公司規定,只能一再的說不好意思,民眾感受到的是一種愛理不理的處理方式。面對突發事件便利超商工讀生的處理態度,影響到品牌形象,品牌人員需要有警覺性。
參考文獻
中文文獻
1.黃燕萍(1999)。中文社會新聞文件資訊擷取。國立雲林科技大學資訊管理所碩士論文。
2.蔡宜芬、蔣以仁、徐珮嵐、范碧琴(2004)。醫學教育上的生醫結構式與非結構式資料之知識建構與管理系統。台北醫學大學醫學資訊研究所、台灣大學醫學工程學研究所。
3.謝邦昌(2014)。SQL Server資料採礦與商業智慧-適用SQL Server 2014/2012。碁峰出版社。
4.趙仲孟、侯迪譯。預測性文本挖掘基礎。西安交通大學出版社。
5.國家教育研究院。文本探勘釋義。國家教育研究院。
英文文獻
1.Dan Sullivan (2001). Document Warehousing and Text Mining. IBM Almaden Research Center.
2.Joachims (1997). A Probabilistic Analysis of the Rocchio Algorithm with TFIDF for Text Categorization. ICML 1997 Proceedings of the Fourteenth International Conference on Machine Learning, 143-151.
3.Sebastiani (2002). Machine Learning in Automated Text Categorization. Consiglio Nazionale delle Ricerche, Italy.
4.Agrawal, Imielinski & Swami (1993). Mining Association Rules between Sets of Items in Large Databases. IBM Almaden Research Center.
5.Buntine (1993). Graphical Models for Discovering Knowledge. Advances in knowledge discovery and data mining, Pages 59-82.
6.Nomoto (2002). MSW Signal-to-Noise Enhancers for Noise Reduction in DBS Reception.
7.Bernhard, G., & Rudolf, W. (1999). Formal Concept Analysis: Mathematical Foundations
8.Aha, D. W. (1997). Lazy learning (pp. 7-10). Kluwer academic publishers.
9.Buntine, W. (1993). Learning classification trees (pp. 182-201). Springer US.
10.Heckerman, D., Geiger, D., & Chickering, D. M. (1995). Learning Bayesian
networks: The combination of knowledge and statistical data. Machine learning, 20(3), 197-243.
11.E. Adams. “A Study of Trigrams and Their Feasibility as Index Terms in a Full Text Information Retrieval System.” PhD thesis, George Washington University, USA, 1991.
12.Mobasher, B., Cooley, R., & Srivastava, J. (2000). Automatic personalization based on Web usage mining. Communications of the ACM, 43(8), 142-151.
13.Aggarwal, C. C., Gates, S. C., & Yu, P. S.L. (2002). U.S. Patent No. 6,360,227. Washington, DC: U.S. Patent and Trademark Office.
14.Michael Cox & David Ellsworth (1997). Application-Controlled Demand Paging for Out-of-Core Visualization. NASA Ames Research Center
15.Luís Torgo.(2003). Data Mining with R:learning by case studies. Chapman & Hall/CRC Data Mining and Knowledge Discovery Series.
● 作者謝邦昌,輔仁大學商學研究所所長,全國意向顧問股份有限公司顧問。本文言論不代表本報立場。論壇歡迎更多聲音與討論,文章請寄editor@ettoday.net
● 本文已發表於商業服務業資訊網http://ciis.cdri.org.tw/index.aspx








讀者迴響